The Web3 Data Economy
Towards a Transparent, Permissionless Ecosystem to Spread the Benefits of AI
[First presented as an invited talk at Web3 Summit, Berlin, 2018. Slides. Video.]
The Shadow Data Economy
The May 2017 cover story of The Economist framed data as “the world’s most valuable resource”. On the back of data, Google, Facebook and a handful of other companies have built businesses with a combined market cap of more than a trillion dollars. For them, data is money: more data means better AI models, means better-targeted ads, means more ad clicks, means more revenue. Follow the money; it leads back to data.
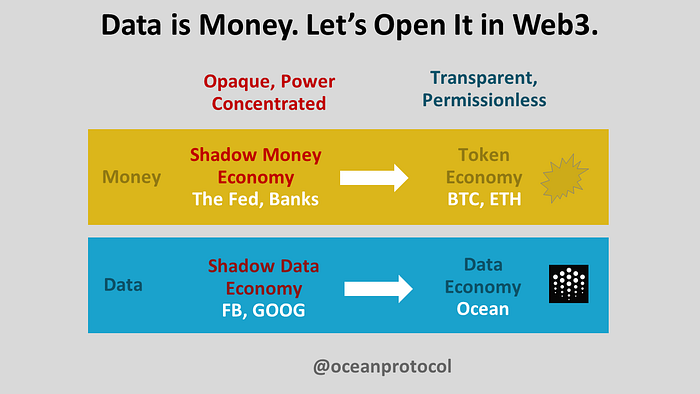
We have a data economy. But it’s a shadow data economy. It’s opaque: Google and the like keep the data to themselves for competitive reasons (data siloes). And, power is concentrated, such as Zuckerberg with his fiefdom of 2 billion people.
Can we shift the data economy to one that is open and permissionless? This is our goal at Ocean Protocol. Fortunately, we have inspiration…
The Money Economy
In 2005, a strawberry picker named Alberto Ramirez with $15,000/year income got a loan to buy a house for $720,000. He had no chance of paying it off. How was this possible? As with data: follow the money. The lenders made tremendous money off the fees. They’d figured out how to get “no chance” loans rated as quality loans with tricks like credit default swaps. Lipstick on a pig.
In 2008, the house of cards came crashing down. Trillions in value were lost. Taxpayers paid the bill. The bankers collected their bonuses and zipped their lips.
It was a shadow money economy with the feds and the banks. It was opaque, with power concentrated in the hands of few.
Enter Bitcoin! Satoshi explicitly pointed to the financial crisis as why she (;) created Bitcoin. Bitcoin has sparked the blockchain movement. As part of that movement, the token economy is opening up money: transparent and permissionless.

The token economy is our inspiration. Just as we’ve been opening up money with the blockchain movement, let’s open up data as well.
Let’s move from a shadow data economy that is opaque with concentrated power, to a Web3 data economy that is transparent and permissionless.

The question is, how? And, what does this actually look like? Surprisingly, it begins with AI (artificial intelligence).
Towards an Open Data Economy
From data, you get value. The crucial step to go from one to the other is AI models. The more data you have, the more accurate your model, the more revenue. AI is the linchpin.

There’s actually tons of data out there within enterprises (the Fortune 500 companies), NGOs, and governments. While they have data, they don’t have AI expertise. They have a tough time attracting AI researchers to come. Why? Because the AI experts have gone off to form their own startups to try to make money from AI.
And those startups are finding — you guessed it — they don’t have any data!
There’s only a small handful of companies that have both data and AI expertise: Google, Facebook and few others. That’s it. This small group of organizations is accruing all the value. AI is the linchpin.
What if we could connect the data haves — people with the data — with the AI haves — people with AI expertise that are starving for data?
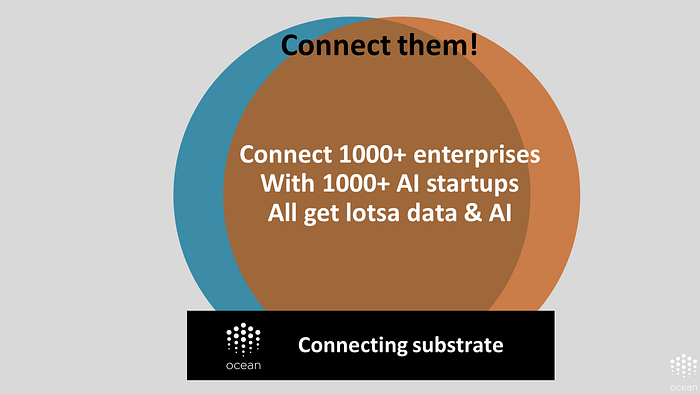
To do so, imagine we could create a substrate that connects these folks. A substrate that helps to equalize the opportunities for leveraging the value of AI and data.
The image below elaborates. On the top are the main users: problem owners, and problem solvers. At the bottom is the connective substrate. In between is connective-tissue middleware: marketplaces side-by-side with AI commons, and data science tools.
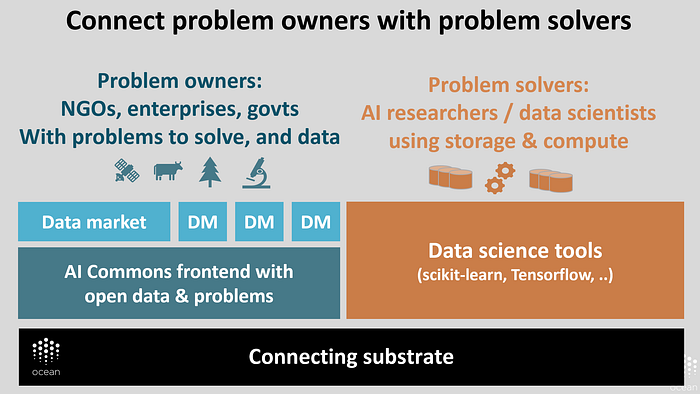
On the problem owner side, governments often have mandates to open up their data. This includes city/municipal governments, all the way up to state/provincial governments and national governments. UN agencies and other NGOs are trying to work with data but, like the enterprises. As described before, AI expertise can be hard for enterprises to attain; this challenge extends to governments and NGOs.
For data, the demand side is easy. AI loves data. More precisely, data scientists know that their AI models can leverage as much data as supplied.
So, it’s really about getting the supply side going. We do this with the yin and yang of priced and free data. Consider having tens or hundreds of data marketplaces, buying and selling data for different industries and verticals — for automotive for medical and so on — as well as a data commons. Side by side with priced data, there will be free data, with incentives for people to supply that free data. And if we put problem definitions into the commons as well, with incentives to solve the problems, we get an AI Commons.
Applications
Let’s explore specific applications for a Web3 data substrate.
Autonomous Vehicles (AVs). AVs promise much greater mobility at lower costs. But we need AV accident rates to be lower. To do so, we need more data: RAND calculated we need 500 billion miles driven. Individually, big automakers have calculated that they’d need 10–20 years to get this much data. BMW, GM and others formed MOBI Foundation as a means to pool their data; and are leveraging Ocean Web3 data substrate.

Health. Earlier detection of cancer leads to earlier treatment, saving lives. A friend of mine builds Genetic Programming models to predict cancer. He’s happy if he has a dataset of 100 points, which, alas, means his models have poor predictive ability. Furthermore, each hospital site has bias due to differences in data collection, like how long a sample sits in a Petri dish before it’s measured. What if we could build models from data in 10 or 100 or more hospitals, while preserving privacy? There’s a way: bring the compute to the data, and build a model across hospitals using federated learning.
This is the direction for ConnectedLife, working on Parkinson’s, and leveraging Ocean Web3 data substrate.
Agriculture. A spinoff from the World Economic Forum called Grow Asia is about giving farmers way more data such that they can more accurately predict how much fertilizer to put in, how much seed to give and so on. They’re iterating with Ocean Web3 data substrate.
Policymaking. For the new European data privacy rules (GDPR), the policymakers designed rules based on the technology of the time. It wasn’t easy. Some of it is perhaps heavy-handed but there are benefits too. But imagine if you could thread the needle better simply because there’s better optionality to address privacy yet get economic benefits from AI& data. The government of Singapore’s data authorities (IMDA) are iterating with Ocean Web3 data substrate for this purpose.

The AI Commons. There’s an “AI for Good” movement, epitomized by the “AI for Good” Summit which last year had >40 UN agencies, learning how to use AI for the UN 17 Sustainable Development Goals (SDGs). Their people have boots-on-the-ground AI-style problems to solve, and they have data. But they aren’t connected to the people that know how to solve the problems — the data scientists. We could do one-off connections via networking. Or we can scale it up in a Web3 data substrate for an AI Commons.

What does a data *economy* look like?
This piece has discussed motivations for an open, permissionless Web3 data economy; inspiration from the money economy; what a data substrate for that economy looks like; and applications. But what does this actually look like as an economy?
Inspiration
We can once again turn to the money economy for inspiration. Let’s unpack elements of the open, permissive token economy. (A simplified model, but nonetheless potentially useful.)
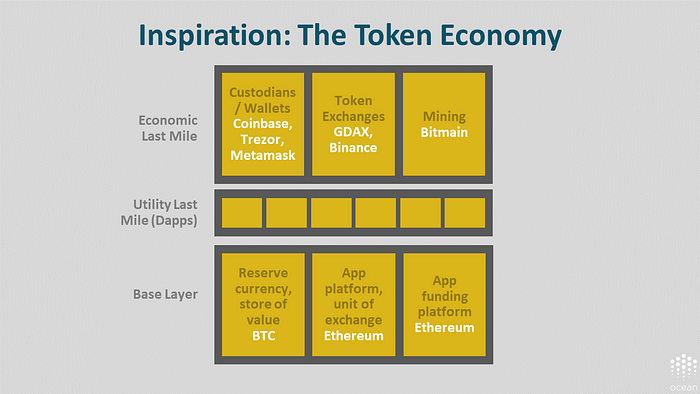
The bottom row is the base layer of the token economy. There’s the reserve currency or store of value: Bitcoin. There’s the app platform, or unit of exchange, like Ethereum. And finally the app funding platform, Ethereum, as well. SAFTs as well these days too.
In the middle row are “last miles” for utility. These are dApps.
On the top row are “last miles” for the economic layer. This includes the custodians / wallets like Coinbase, Tresor, and Metamask. It includes token exchanges like GDAX and Binance. Finally, it includes mining such as Bitmain.
What if the data economy looked like the token economy? (At least as a first approximation.) Let’s picture this, in the image below.
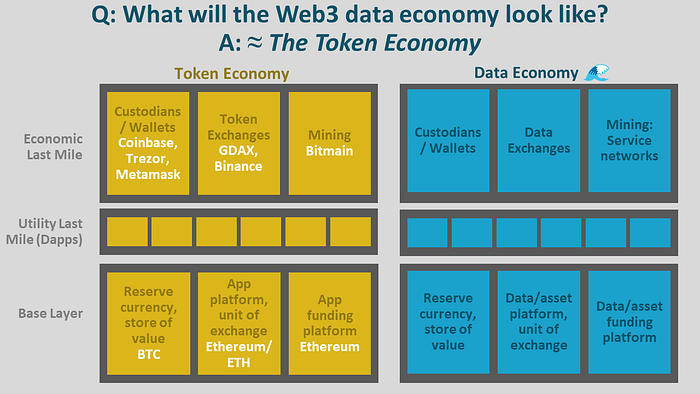
Once again we have the reserve currency, the unit of exchange, the data or asset funding platform and then the utility & economic last miles.
Elements of a Web3 Data Economy
Next, how do we instantiate this data economy? We need to fill in each of the blue boxes. Let’s explore a possible way to do it, based on the current (but subject to change!) design of Ocean Protocol.
Users can stake on data assets in the context of bonding curves (details). These are used as a signal for relevance of a dataset X. The more you stake on X, the more relevant or popular you believe it will be, and the more block rewards you’ll expect when you serve it up.

A bonding curve (BC) is an automated market maker, a robot that’s always there to buy or sell one token for another, for a price. For data asset X, the BC starts off selling tokens called “ḌX”, drops of X, in exchange for Ocean tokens “Ọ”. There are initially 0 ḌX. But once someone start buying ḌX for cheap, the BC mints more tokens. ḌX tokens get more expensive with each new purchase. If you sell some ḌX, they burns. It’s a continuous cycle of minting or burning.
Base layer: Data asset funding platform. Each time you publish a data asset and initialize a bonding curve, you’re also starting a “mini ICO”. People can purchase tokens, where each token carries some rights to expected income from block rewards. Initially, there’s no tokens. But as soon as someone starts staking into it, then it’s issuing those tokens of that data asset.
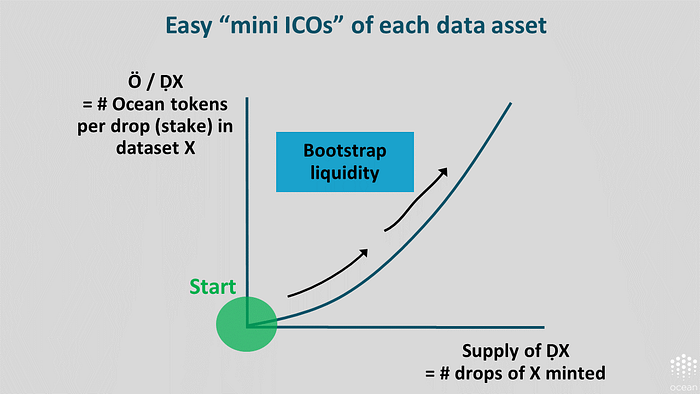
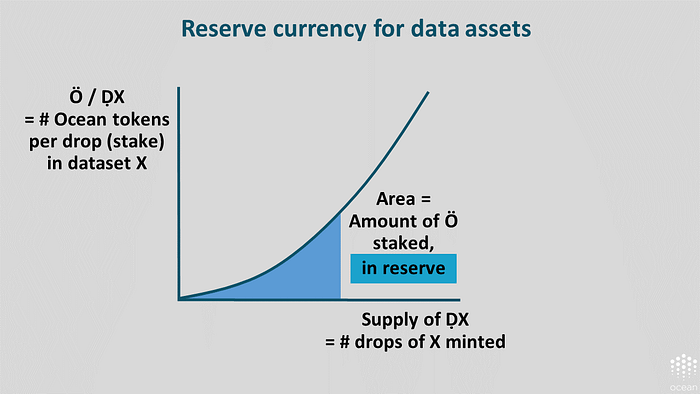
Base layer: Reserve currency. Bonding curves have built-in reserve currency behavior. The area under the curve is actually a reserve, tying up liquidity. The more tokens that have been staked into one of these bonding curves, the more you have in reserve currency.
Base layer: Unit of Exchange. A unit exchange comes from buying and selling data, and services for storage, compute, etc. The Web3 data substrate has mechanisms for doing so.
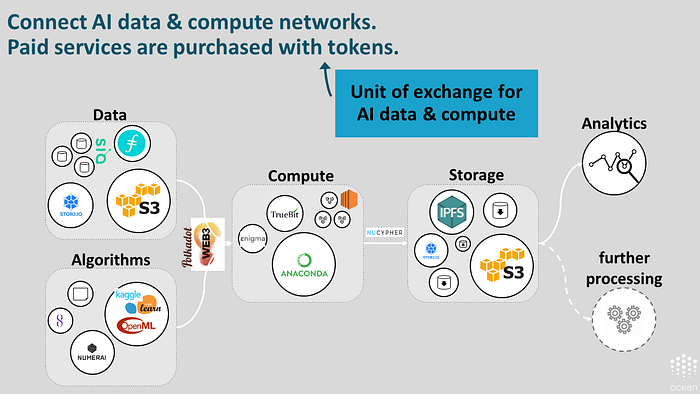
To summarize, the Web3 data substrate fulfills the base layer of the data economy in terms of reserve currency /store of value, unit of exchange, and funding platform.
On top of this base layer are the economic and utility “last miles”, as shown below. There’s a lot going on here; let’s unpack it.
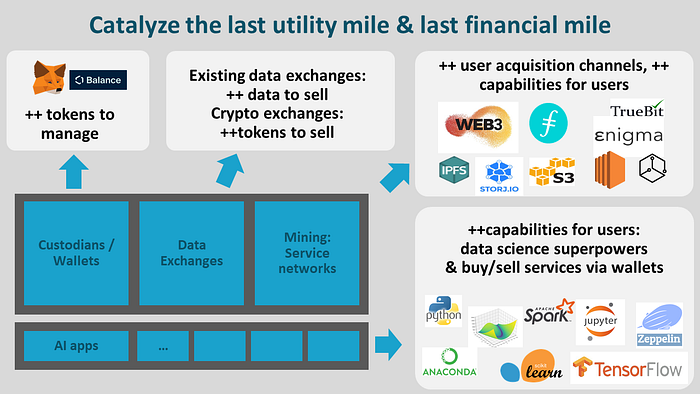
Economic last mile: Custodians/Wallets. Tokens can be managed with traditional crypto tools, like Metamask or Balance, or or even new wallets that are designed just for the data economy. We think we have the long tail of tokens right now in the token economy. In a data economy, we could have get orders of magnitude more tokens. There could be ten thousand data sets or even a million, each with its own token. It’ll be interesting to see how that gets managed. Consider this a challenge for wallet builders!
Economic last mile: data exchanges. Existing centralized data exchanges, decentralized data exchanges may find value increasing their data supply from the Web3 data substrate. Crypto token exchanges may find value in having *way* more tokens on their platforms.
Economic last mile: service networks. In a Web3 data economy, “miners” are actually providers of data, and storage & compute services. They have three potential benefits: a new (potentially big) channel for customer acquisition; new capabilities for their customers (e.g. on-premise compute); and new revenue for them/their users via block rewards.
Utility last mile. This is about about new powers for data scientists: more data, provenance, and new income opportunities. (Details.) Therefore, data science toolmakers may find benefit in leveraging a Web3 data substrate to better serve their data science users. We also expect interesting combinations of tools for economic and utility last mile, such as a Jupyter notebook with a built-in wallet and means to buy & sell data. Individual notebooks themselves, with their algorithms & know-how, will probably be interesting to buy & sell!
In short, the Web3 data economy could a lot like the token economy.
Conclusion
Data is money. Let’s open it in Web3. We moved from a shadow money economy to a token economy. Let’s do the same thing with data. Let’s move from a shadow data economy to a transparent and permissionless data economy. A Web3 data economy.
Other Media
Thanks to the Web3 Foundation for the opportunity to speak about the Web3 data economy at their inaugural Web3 Summit, Oct 2018, in Berlin. Here are the slides and video from that talk.
Acknowledgements
Many people have contributed thinking to this piece, thanks to all of you. Special thanks to Dimi de Jonghe and Bruce Pon for having the biggest impact on the thinking in the piece. Thanks to Cristina Pon and Daniel Lustig for helping to convert this from a talk to text. And a big thanks the team at Ocean Protocol for working like crazy towards building the substrate for the Web3 data economy, and all of the supporters around it.
Follow Ocean Protocol via our Newsletter and Twitter; chat with us on Telegram or Discord; and build on Ocean starting at our docs.

